

Abstract
This paper describes a proposal for an AWS-based data lake: a central repository for storing data of all types and sizes: raw data, analytics and business data, each at its own tier. It serves as a basis for the development of data-driven products, the execution of real-time and batch analyses, data mining to gain new insights and for the development of machine learning based products and services.
The proposed architecture decouples storage from compute and allows the storage to be scaled independent. A central data catalog provides automatic crawling, cataloging, and indexing of data. Lifecycle policies enable cost-effective data storage and
archiving.
Compute is serverless as far as possible maintaining as little infrastructure as possible. Infrastructure-based services can be used for special tasks if required, e.g. for real-time applications, time-consuming batch tasks, explorative data mining or the training of machine learning algorithms.
The architecture provides a unified interface for various types of data. It allows data to be queried in place, i.e. analyses can be
carried out without having to move data to separate analysis systems. Data scientists, business analysts and developers can access data with their choice of tools and frameworks.
This proposal is intended to stimulate discussion about the best possible Data Lake architecture before all our data is transferred to the AWS cloud.
Central Data Storage
The central data storage consists of a 3 tier architecture that separates raw and processed data. On a third level, products and services are supplied with optimally adapted data. A common data catalog provides an interface of all assets stored.
Data Catalog
The AWS Glue data catalog provides a single view across all data in the data lake. It contains table definitions and custom metadata. AWS Glue crawlers automatically detect, catalog and index new data. AWS Glue makes the data-lake searchable and
available for ETL.
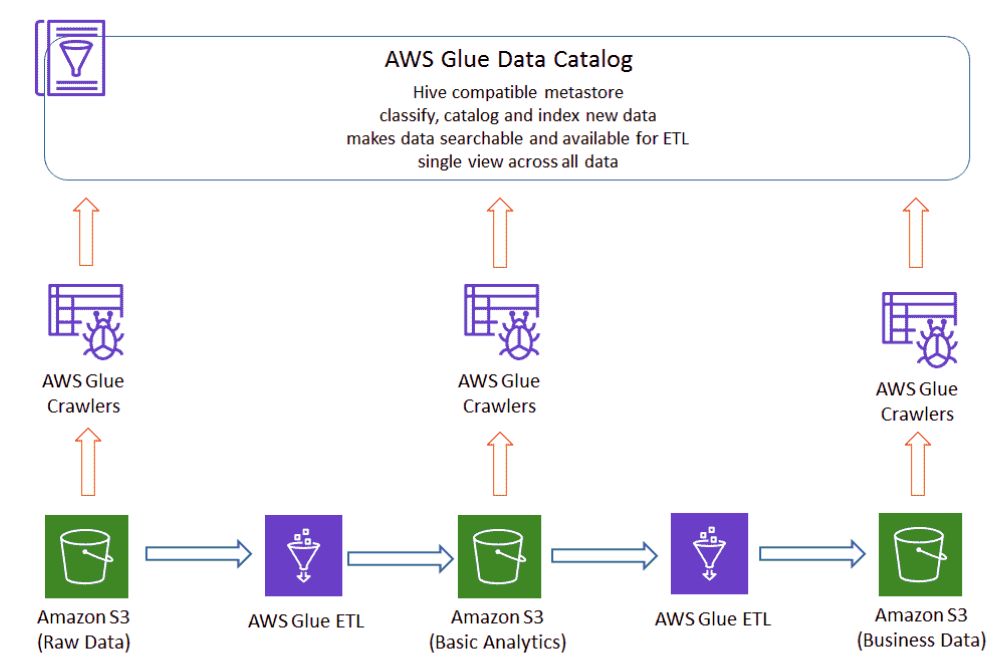
The following diagram illustrates the properties of the different levels of the data store. Examples serve to better understand what is stored at each level.
Important is the separation between raw and cleaned data on the first two levels. The third level is organized according to the data requirements of applications. Each data source contains only the specific data required for that application, optimally partitioned and structured. AWS Glue ETL jobs ensure data consistency between layers.

Processing and Compute
The compute architecture comprises several service-groups for data ingestion, catalog, storage, search, processing and analytics.
Core Layers
The services of the core layers cover all the essential tasks for the collection, cataloging and storage of raw data as well as for their transformation into general analytics and product-optimized business data. The services enable all data to be queried in-place without having to move data to separate analysis systems. Data scientists, business analysts and product developers can access data via standard interfaces with their choice of analysis tools and frameworks.
A key feature in the selection of the AWS compute services is cost-efficiency. As far as possible, services should be serverless or only launched when needed (e.g. transient clusters).
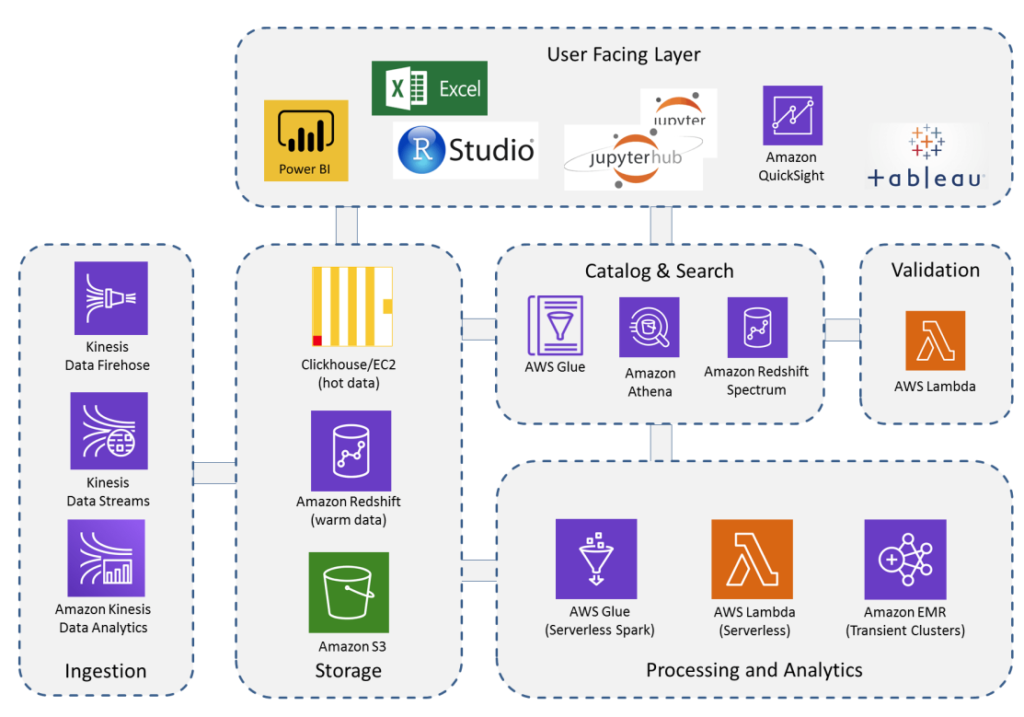
Kinesis Data Streams allows real-time ingestion of streaming data and continuous processing by multiple consumers simultaneously.
Kinesis Data Firehose supports efficient near real-time loading of data streams into Amazon S3 or Amazon Redshift. It provides data conversion, transformation through AWS Lambda as well as data compression. It is fully managed and scales automatically.
Kinesis Data Analytics can be used to perform real-time analytics on data streams using standard SQL. The service enables easy generation of time-series analytics (calculating metrics over time windows), feeding real-time dashboards, or creating real-time metrics (for use in real-time monitoring, notifications, and alarms). Amazon Athena is a service that uses standard SQL to query big data directly within Amazons S3. Athena is serverless, so you pay only for the queries that you run. It is integrated with the AWS Glue Data Catalog and enables a very cost-efficient querying of columnar data.
Amazon Redshift provides support for frequently accessed (hot) data and efficient handling of small mutable data and reporting workloads. It can be quite expensive due to the simultaneous scaling of compute and storage.
Amazon Redshift Spectrum enables you to run Amazon Redshift SQL queries directly against data stored in Amazon S3. It can run queries that span both frequently accessed data stored in Amazon Redshift and full data sets stored in Amazon S3.
Clickhouse (on EC2) is a high-performance, extremely fast column oriented database. It enables explorative interactive analysis and real-time data mining without restrictions of predefined partitions or interleaved sort keys. It requires installation on suitable EC2 instances and causes corresponding costs. It should therefore only be used for tasks for which there are no alternative AWS services.
Amazon EMR clusters can be used to distribute data-intensive batch jobs across multiple compute nodes, e.g. to clean up and convert large datasets. Transient clusters are started on demand for a specific task and shut down automatically when the task is complete.
Additional Analytics & Processing Services
If required, additional infrastructure-based services can be used, e.g. for compute intensive real-time applications, time-consuming batch tasks, or explorative data mining.
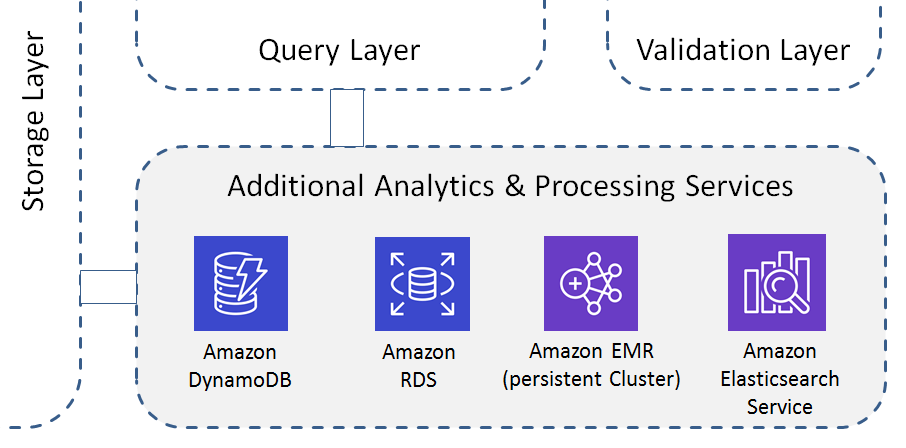
Amazon DynamoDB is ideal for applications that need a flexible NoSQL database with low read and write latencies, and the ability to scale storage and throughput up or down as needed. It has become the de facto database for powering Web and mobile
backend. A typical application area is real-time analytics. Amazon DynamoDB lets you increase throughout capacity when you need it, and decrease it when you are done, with no downtime.
Amazon RDS is a hosted relational database. But since these databases are row-oriented, they are rarely used in the big data area. An exception is the use of PostgreSQL/PostGIS in the context of spatial analytics and geo-based analyses.
Amazon ElasticSearch is a fully managed service to search, analyze, and visualize it in real time, e.g. for log and clickstream analytics or anomaly detection.
Machine Learning & AI Layers
Machine learning and data science tasks are performed by fully managed AWS machine learning services, AI services, pre-configured AWS deep learning instances (AMIs) or EMR clusters for distributed Spark/ML based data science tasks.
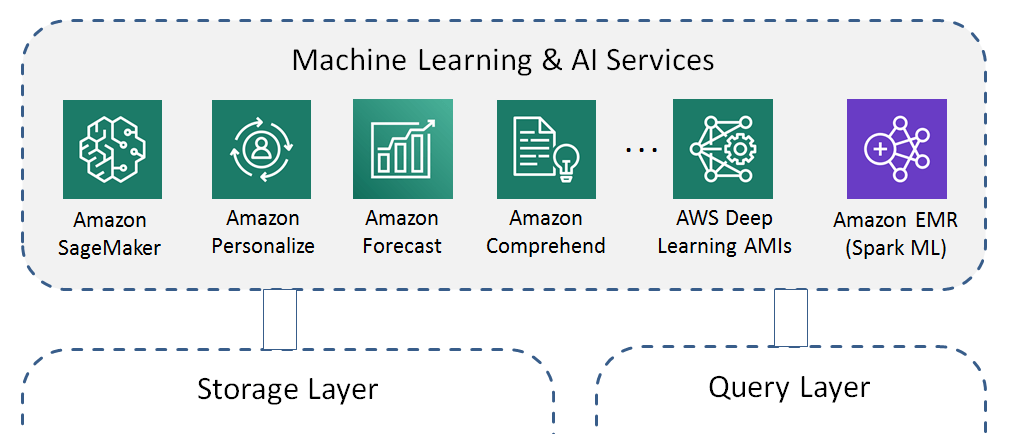
Amazon SageMaker is a scalable, fully managed machine learning service. It can be used to build, train, and deploy machine learning models. It provides many built-in, high performance machine learning algorithms and has a broad framework support.
Other Amazon AI Services provide support for image analysis, natural language processing, personalized recommendations, or forecasting without the need for in-depth machine learning knowledge.
AWS Deep Learning AMIs support data scientists with Amazon EC2 instances pre-installed with popular deep learning frameworks such as TensorFlow, PyTorch, Apache MXNet, or Keras to train sophisticated, custom AI models.
Spark ML on Amazon EMR includes MLlib for many scalable machine learning algorithms.