
Modern Data Stack
The Modern Data Stack fits perfectly into the shift from a technology-centered vision to a business-centered vision and allows everyone to use data to increase the overall performance of the company.
The Modern Data Stack is characterized by its modularity, allowing companies to select the tools best suited to their specific needs. The technologies used in the MDS emphasize an excellent user experience, making them easier to adopt by both technical and non-technical teams.
Each component of the MDS fulfills a specific function, from data ingestion to transformation and visualization. This modularity ensures better control, ease of implementation, and scalability, as each component can be adjusted or modified according to needs without affecting the entire system.

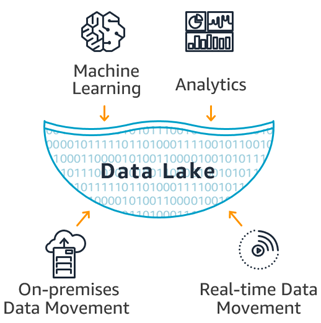
AWS Data Lake Architecture
Data Lake on AWS automatically configures the core AWS services necessary to easily tag, search, share, transform, analyze, and govern specific subsets of data across a company or with other external users.
Data lakes on AWS help you break down data silos to maximize end-to-end data insights. With Amazon Simple Storage Service (Amazon S3) as your data lake foundation, you can tap into AWS analytics services to support your data needs from data ingestion, movement, and storage to big data analytics, streaming analytics, business intelligence, machine learning (ML), and more
Introduction to kestra
Kestra is an open-source, event-driven data orchestrator that strives to make data workflows accessible to a broader audience. The product offers a declarative YAML interface for workflow definition in order to allow everyone in an organization who benefits from analytics to participate in the data pipeline creation process.
With its intuitive interface and powerful features, Kestra enables users to build tailored workflows without the need for programming languages or deployment. In this article, we will explore the key features of Kestra and how it can benefit data engineers and developers.

Save cash by using the cache.
In a traditional on-premise data warehouse, inefficient SQL queries often result in longer execution times. However, with modern cloud-based data warehouses like Snowflake, inefficient queries lead to higher financial costs due to increased credit consumption. This difference highlights the importance of not only writing optimized SQL queries but also understanding Snowflake’s architecture and its various caching mechanisms to fully utilize pre-calculated query results.
In this article, we’ll explore Snowflake’s key caching layers—Metadata Cache, Query Result Cache, and Warehouse Cache—and how each can help reduce credit consumption while improving performance.
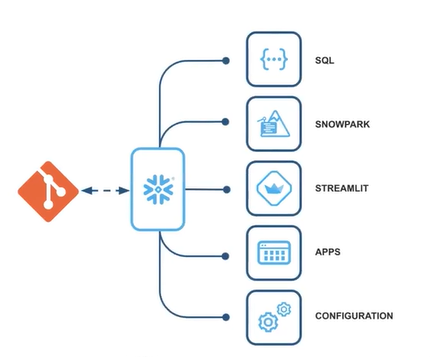
Integrating Git with Snowflake: A Guide for Collaboration
In today’s fast-paced data landscape, effective version control and seamless integration are paramount.
Git is crucial for version control and collaborative development, while Snowflake offers powerful cloud-based data warehousing solutions. We will provide an overview of the key elements, processes, steps, and use cases involved in synchronizing data between Git and Snowflake, highlighting the importance of seamless integration in modern data management workflows.
Snowflake Iceberg Tables
Iceberg is an open-source project hosted by the Apache Foundation. It initially started as a Netflix OSS project and eventually moved to a community project. From what I can see, it is genuinely a super high-performance format for those who have really large analytic tables.
The Snowflake Data Cloud continues to stand out as a pioneer, consistently introducing innovative features to simplify and optimize data storage and compute workloads. One such feature recently added by Snowflake is to support the Iceberg table format.
